







امروز بالاخره MI300X منتشر شد و با صدای بلند منتشر شد. مشتریان زیادی اعلام شدهاند که در اینجا درباره حجم و ASP آن صحبت کردیم، از جمله افرادی مانند اوراکل، متا و مایکروسافت. ما پیکربندی و معماری را در ماه ژوئن ارسال کردیم، بنابراین در حالی که جزئیات معماری سطح پایین جدیدی در پایان این امروز وجود دارد، ما بیشتر روی عملکرد، هزینه و نرم افزار تمرکز خواهیم کرد. همچنین خبرهای بزرگ در مورد اتحاد ضد انویدیا AMD + Broadcom.
در مشخصات خام، MI300X با 30 درصد FP8 FLOPS بیشتر، 60 درصد پهنای باند حافظه بیشتر و بیش از 2 برابر ظرفیت حافظه بر H100 غالب است. البته MI300X در مقابل H200 فروش بیشتری دارد که شکاف پهنای باند حافظه را به محدوده تک رقمی و ظرفیت به کمتر از 40 درصد کاهش می دهد. متأسفانه MI300X تنها توانست به 5.3 ترابایت بر ثانیه پهنای باند حافظه را به جای 5.6 ترابایت بر ثانیه که در ابتدا هدف گذاری شده بود، برساند.


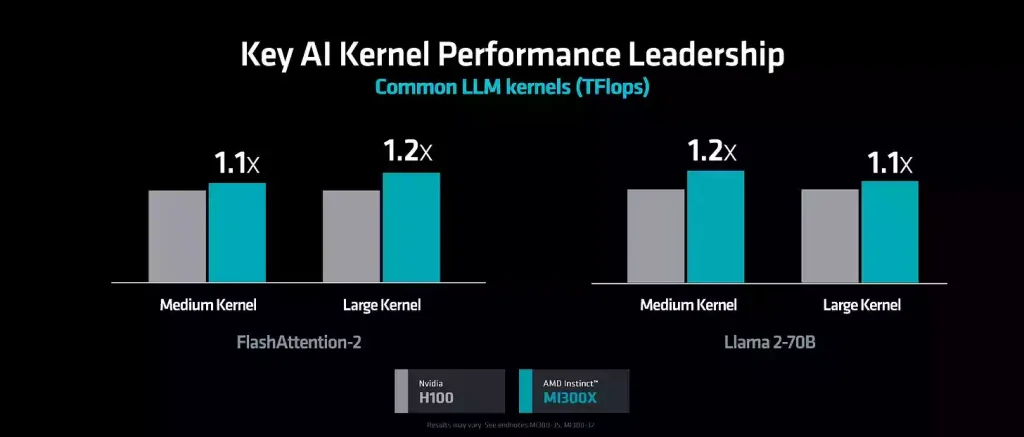
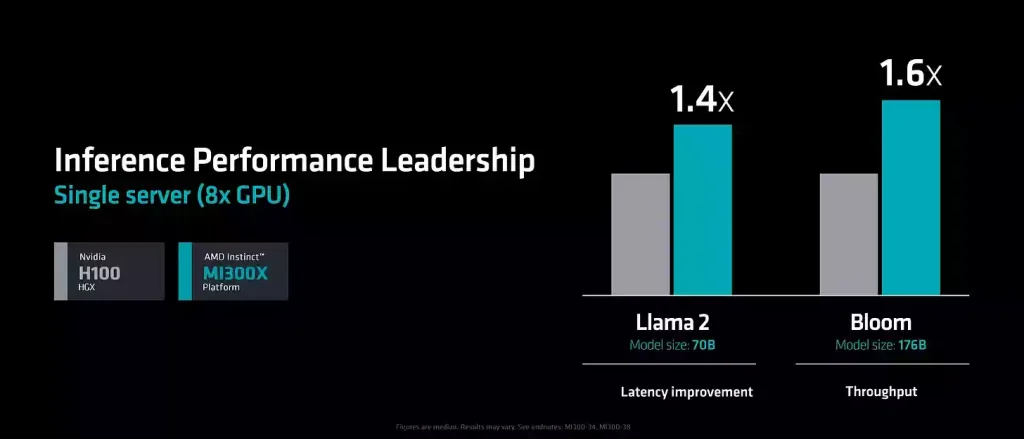
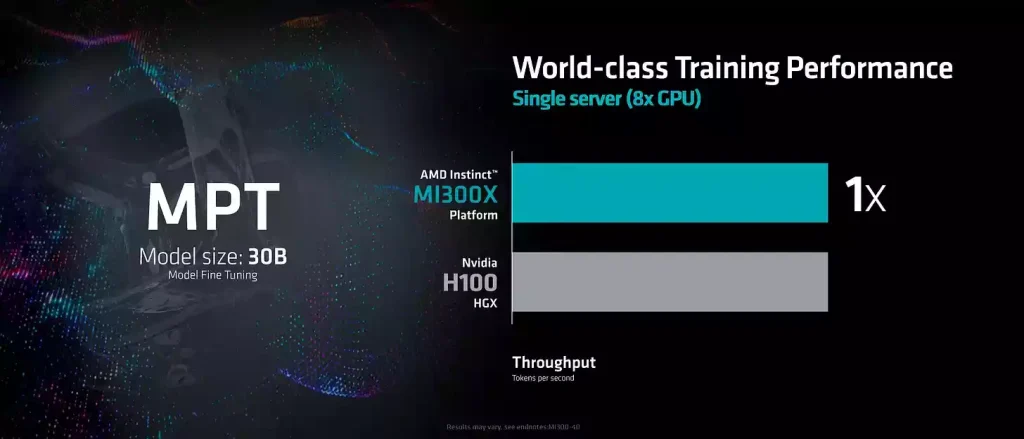
البته FLOPS، ظرفیت و پهنای باند فقط قابلیتهای بالقوه هستند. AMD چند بنچمارک مختلف را نشان داد، موضوع اصلی این است که آنها هنوز در مقایسه با عملکرد تئوری کمی پایینتر هستند.
FlashAttention2 – این فقط پاس رو به جلو است، استنتاج IE، نه آموزش. قابل توجه است زیرا تقریباً هر بنچمارکی که AMD به اشتراک میگذارد فقط پاس رو به جلو بود. مزیت عملکرد 10٪ تا 20٪ است، بسیار کمتر از مشخصات خام.
LLAMA2-70B – باز هم پاس رو به جلو فقط برای کرنل های خاص، نه مدل کامل، و دوباره 10% تا 20% عملکرد. اینها بیشتر بارهای کاری محدود به محاسبه هستند، نه محدود به حافظه.









دیدگاهتان را بنویسید